「翻译」Cognition: 为 Claude Sonnet 4.5 重构 Devin:经验与挑战
我们为 Claude Sonnet 4.5 重构了 Devin。新版本在我们的初级开发人员评估 (Junior Developer Evals) 中速度提升了 2 倍,表现提高了 12%,现已在“智能代理预览”(Agent Preview) 中提供。对于喜欢旧版 Devin 的用户,该版本仍然可用。
2025年9月29日 Cognition 团队
我们为 Claude Sonnet 4.5 重构了 Devin。
新版本在我们的初级开发人员评估中速度提升了 2 倍,表现提高了 12%,现已在“智能代理预览”中提供。对于喜欢旧版 Devin 的用户,该版本仍然可用。
为什么选择重构,而不是简单地替换成新的 Sonnet 模型就草草了事?因为这个模型的运作方式与众不同——它打破了我们对智能代理应如何构建的固有设想。以下是我们的心得:
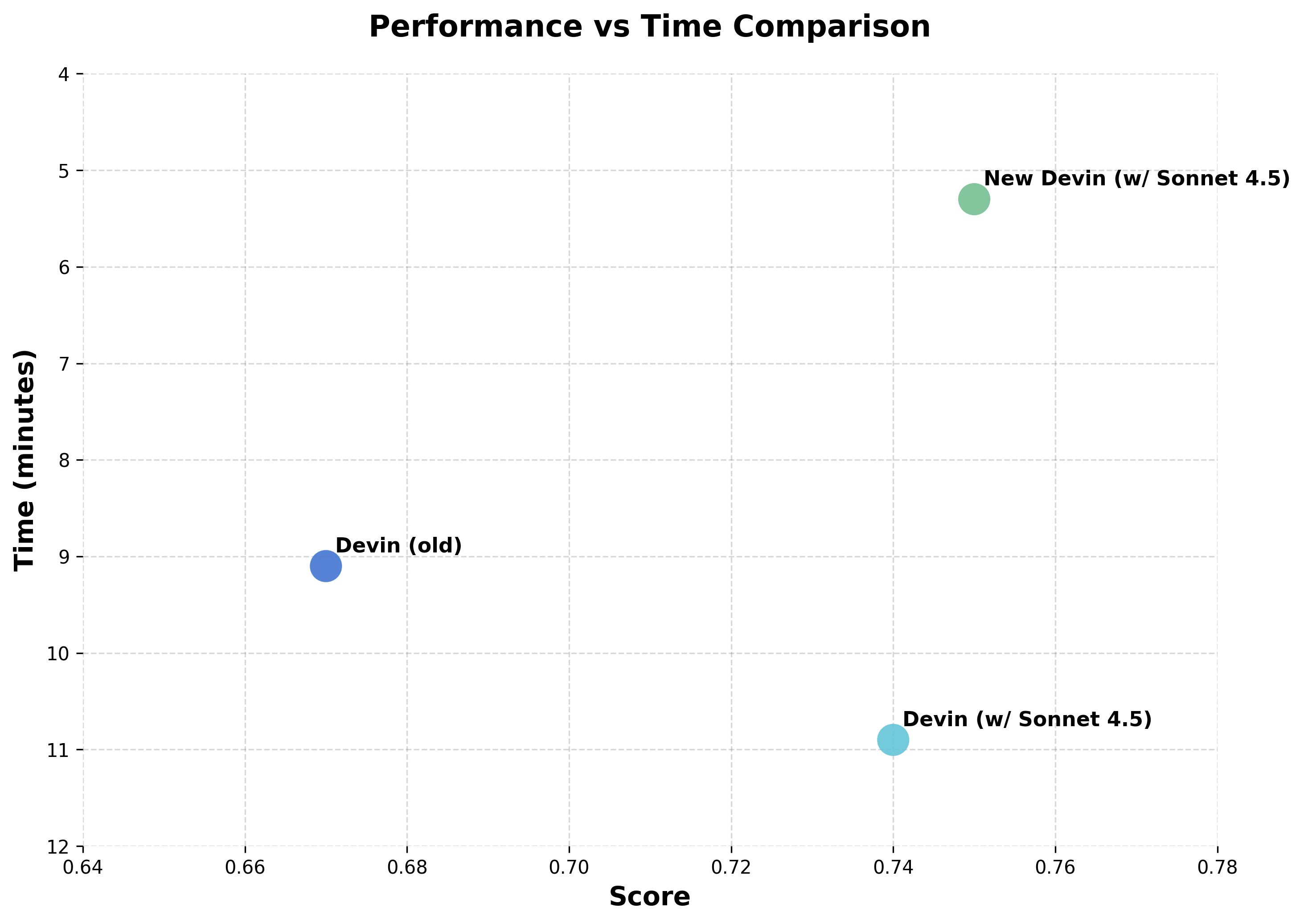
因为 Devin 是一个会规划、执行和迭代的智能代理,而不仅仅是自动补全代码(或充当一个“副驾驶”),所以我们得以用一个独特的窗口来观察模型的能力。每一次改进都会在我们的反馈循环中产生复合效应,让我们了解到真正发生了哪些变化。在 Sonnet 4.5 上,我们看到了自 Sonnet 3.6(Devin 正式版所使用的模型)以来最大的飞跃:规划性能提升了 18%,端到端评估得分提高了 12%,长达数小时的任务会话也变得更快、更可靠。
为了实现这些改进,我们不仅需要围绕模型的一些新功能重构 Devin,还必须针对一些我们在前几代模型中从未注意到的新行为进行调整。我们将在下面分享一些我们的观察:
模型能意识到自己的上下文窗口
Sonnet 4.5 是我们见过的第一个能意识到自身上下文窗口的模型,这一点塑造了它的行为方式。我们观察到,当接近上下文限制时,它会主动总结自己的进展,并更果断地实施修复以完成任务。
这种“上下文焦虑”实际上可能会损害性能:我们发现,当模型认为自己接近窗口末尾时,即使还有足够的空间,它也会选择走捷径或将任务半途而废。
为了克服这种行为,我们最终采用了相当激进的提示 (prompting) 方式。即便如此,我们发现仅在对话开始时给出提示是不够的——我们必须在提示的开头和结尾都加上提醒,以防止它过早地结束工作。
在研究解决这个问题的方法时,我们发现了一个意想不到的技巧,效果很好:启用 100 万 token 的测试版,但将使用量上限设为 20 万。这让模型认为自己还有充足的余地,从而表现正常,避免了由焦虑驱动的捷径行为或性能下降。
这种行为对我们如何围绕上下文管理进行架构设计具有实际意义。在规划 token 预算时,我们现在需要考虑模型自身的意识:了解它何时会自然而然地想要进行总结,以及何时我们需要通过上下文压缩进行干预。
有趣的是,该模型总是低估自己剩余的 token 数量——而且这些错误的估计非常精确。
模型会做大量笔记
Sonnet 4.5 最显著的变化之一是,它会通过查阅文档和进行实验,积极地尝试构建关于问题领域的知识。
为自己写笔记
无需提示,该模型就会将文件系统视为其内存。它会频繁地撰写(或想要撰写)摘要和笔记(例如 CHANGELOG.md, SUMMARY.md,但不会是 CLAUDE.md 或 AGENTS.md),既是为了方便用户,也是为了自己将来参考。这表明该模型经过训练,倾向于将状态外部化,而不是纯粹依赖上下文。当模型接近其上下文窗口末尾时,这种行为会更加明显。
当我们看到这一点时,我们对是否有可能移除我们自己的一些内存管理机制、让模型来处理这个问题产生了兴趣。但在实践中,我们发现这些摘要不够全面。例如,它有时会转述任务,却遗漏了重要细节。当我们依赖模型自己的笔记而没有使用我们的压缩和摘要系统时,我们观察到性能下降和特定知识的缺失:模型不知道自己不知道什么(或者将来可能需要知道什么)。通过提示很可能会改善这些笔记的质量。只是不要指望能免费得到一个完美的系统。
在某些情况下,有点滑稽的是,我们看到智能代理花在写摘要上的 token 比实际解决问题所用的还要多。我们还注意到,模型的努力程度并不均衡:上下文窗口越短,模型生成的摘要 token 往往越多。
在我们的测试中,我们发现这种行为在某些情况下很有用,但当我们明确指示智能代理使用其先前生成的状态时,其效果不如我们现有的内存系统。
这是一个有趣的范式,也是模型开发的一个新方向,特别是对于更简单的智能代理架构或围绕子代理委托构建的系统而言。这显然是 Anthropic 的一个新方向:很可能指向一个未来,即模型更具上下文感知能力,并且这将成为多个智能代理相互通信的方式。强化学习 (RL) 的训练尚未完全发展到让这种方式变得可靠的程度,但我们将持续关注其演变。
通过测试创建反馈循环
Sonnet 4.5 在编写和执行简短脚本和测试以创建反馈循环方面表现得更为主动,并且在何时使用此功能上展现了良好的判断力。这通常能提高长时间运行任务的可靠性,尽管我们偶尔也看到它在调试时尝试过于“有创意”的变通方法。例如,在编辑一个 React 应用时,我们注意到模型会获取页面的 HTML,以便在过程中检查自己的工作,确保行为是正确的。在另一个案例中,为了修复一个看似无害的、与两个本地服务器试图在同一端口上运行相关的错误,模型最终利用这种行为创建了一个过于复杂的自定义脚本,而不是解决根本问题(终止进程)。
模型可以并行工作
Sonnet 4.5 能通过并行工具执行来高效地最大化每个上下文窗口内的操作——比如一次运行多个 bash 命令,同时读取多个文件等等。模型不会严格地按顺序工作(完成 A,然后是 B,然后是 C),而是在可能的情况下将工作重叠进行。它在自我验证方面也表现出不错的判断力:边工作边检查。
这一点在 Windsurf 中非常明显,并且是在 Devin 现有并行能力上的一大改进。话虽如此,这里也存在权衡。并行处理会更快地消耗上下文,从而导致我们前面提到的“上下文焦虑”。但是,当模型在空的上下文窗口中运行时,这种更并发的方法会让会话感觉更快、更高效。这是一个微妙的转变,但它影响了我们对架构的思考。
该模型似乎也经过训练,在上下文窗口的早期阶段会更快地用尽并行工具调用,但随着接近极限时会变得更加谨慎。这向我们表明,它经过训练能够意识到其工具调用将产生多少输出 token。
我们下一步探索的方向
这些行为开辟了许多有趣的途径,我们尚未能全部探索。以下是我们渴望继续测试的一些方向:
- 子代理和上下文感知的工具调用。 模型在判断何时外部化状态和创建反馈循环方面的能力有所提高,这表明它可能更有效地处理子代理委托。然而,正如我们所知,在使用子代理时必须非常小心,因为上下文和状态管理会迅速变得复杂。Sonnet 4.5 似乎对适合委托的任务类型有更清晰的认识,这可能使其更具实用性。
- 元智能代理提示 (Meta-agent prompting)。 我们对该模型如何处理关于智能代理工作流程的元层面推理特别感兴趣。早期实验表明,它与验证系统配合得很好——让模型能够对其自身的开发过程进行推理,而不仅仅是执行任务。
- 上下文管理模型。 Sonnet 4.5 似乎对如何管理自身上下文有了一些初步的直觉。或许可以训练专门用于智能上下文管理的定制模型,从而实现更快、更好的性能。
随着我们了解到哪些方法有效(哪些无效),我们会分享更多信息。同时,我们很高兴你能试用搭载了 Sonnet 4.5 的新版 Devin 和 Windsurf。
标签:
- 公告 关注我们:
- Twitter [ x ]